When I stopped thinking about latency the way I always had
For most of my career, latency was a number. You measured it, set a threshold, and if the number was too high you went to fix it. A request goes in, a response comes out. Either it’s within acceptable range or it isn’t.
Then I started building AI into an internal operations platform.
The platform handled the usual enterprise stuff: user provisioning, license management, access control, integrations with other systems. Real operational stuff, used by real people. At some point the idea came up to let users interact with it through a chat interface. Instead of navigating menus, they could just ask: who has this license? provision this user, revoke this access.
Simple idea. But building it changed how I think about performance.
The first thing I noticed was that the system felt slower. And it was. But not because something was wrong.
A traditional API executes predefined logic. It knows what to do before the request arrives. An agent has to figure that out. It has to read the prompt, figure out which tools matter, pull context, call APIs, reason about what comes next, and only then generate something. And that path isn’t fixed. The same question tomorrow might take a completely different route.
Users didn’t seem to care. That surprised me. Two seconds in a normal interface and people assume something broke. The same two seconds in a chat interface, where text is streaming in progressively, feels like the system is thinking. The latency is identical. The experience is completely different.
There’s a metric in AI systems called Time To First Token. It’s the time between sending a prompt and seeing the first word of the response. Even if the full response takes 10 seconds, a short TTFT creates the perception of responsiveness. The system isn’t fast. It just starts talking before it’s done thinking.
That realization had a direct consequence. The chat interface I was working on had a loading state: the user sent a message, a spinner appeared, and then the full response showed up at once. I changed that. Instead of waiting for everything to be ready, the interface started rendering partial responses as they arrived. The difference in perceived quality was immediate. Same backend, same latency, completely different feeling.
But streaming wasn’t the answer to everything. For short responses, rendering text word by word actually felt worse. It looked like the system was struggling. We had to work with the UX team to figure out where streaming helped and where it created more noise than clarity. That was the part I hadn’t anticipated: the same technique that improved one scenario degraded another.
That was a shift for me. I had always thought about latency as a backend problem. Something you solve with better infrastructure, smarter caching, more efficient queries. And those things still matter. But in an agentic system, latency is also a UX problem. An orchestration problem. Sometimes a product-design problem. You’re not optimizing for execution speed. You’re optimizing for how the system communicates while it’s still figuring things out.
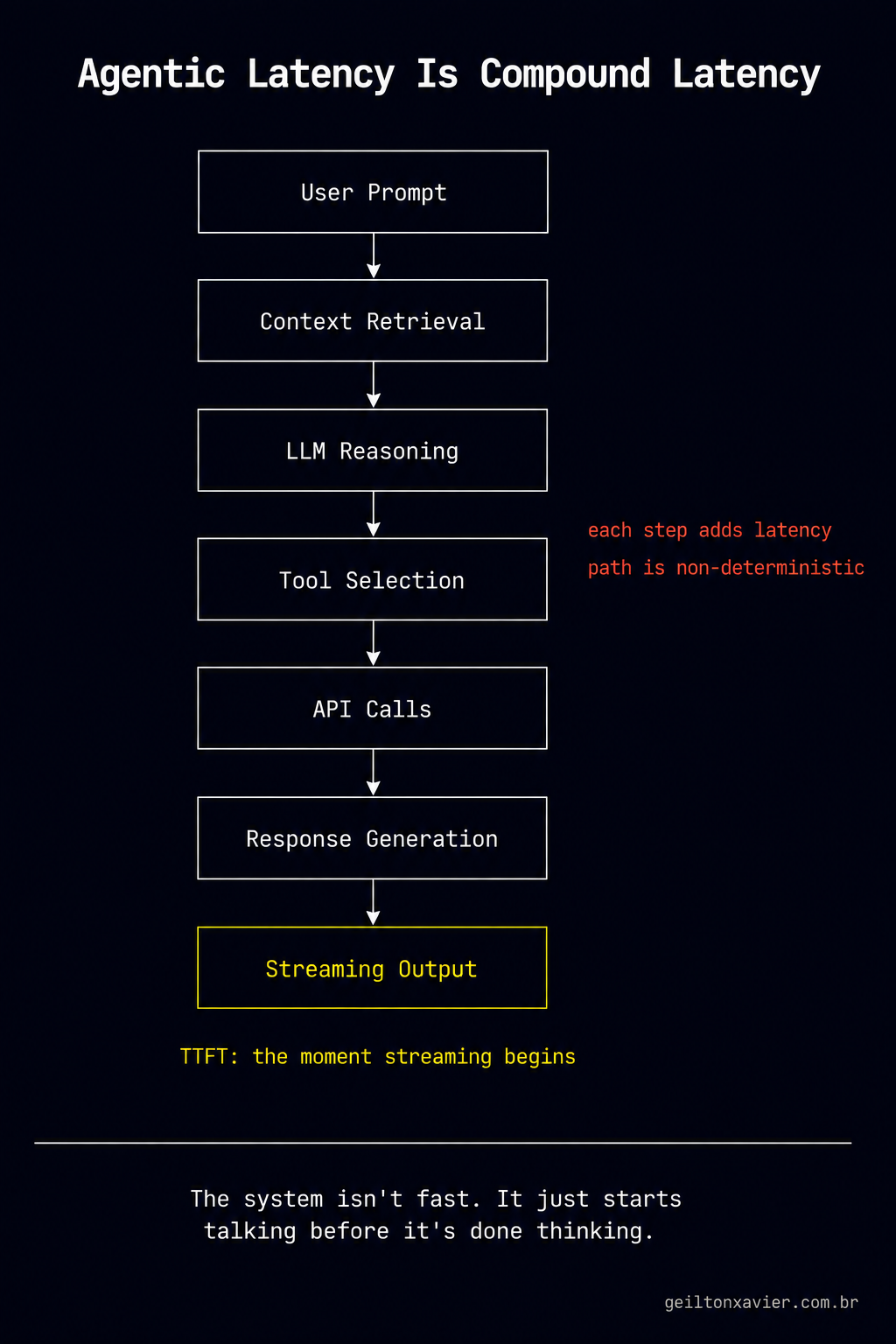
I don’t think traditional performance engineering goes away. It compounds. Every stage in an agentic pipeline, context retrieval, LLM reasoning, tool selection, API calls, response generation, adds its own latency. And unlike a standard request pipeline, those stages are non-deterministic. You can’t fully profile them in advance. You learn to reason about them probabilistically.
What changed for me isn’t a conclusion. It’s a question I now ask earlier in the process.
Not just “how fast does this respond?” but “how does this communicate while it’s working?”
Those are different problems. And I’m still learning how to think about them.