AI Reliability in Software Engineering: The Gap Between Assistant and Actor
When you use AI as an assistant, a wrong answer is annoying. When AI is an actor in your production system, a wrong answer has consequences.
That distinction matters more than most architectural discussions about AI acknowledge.
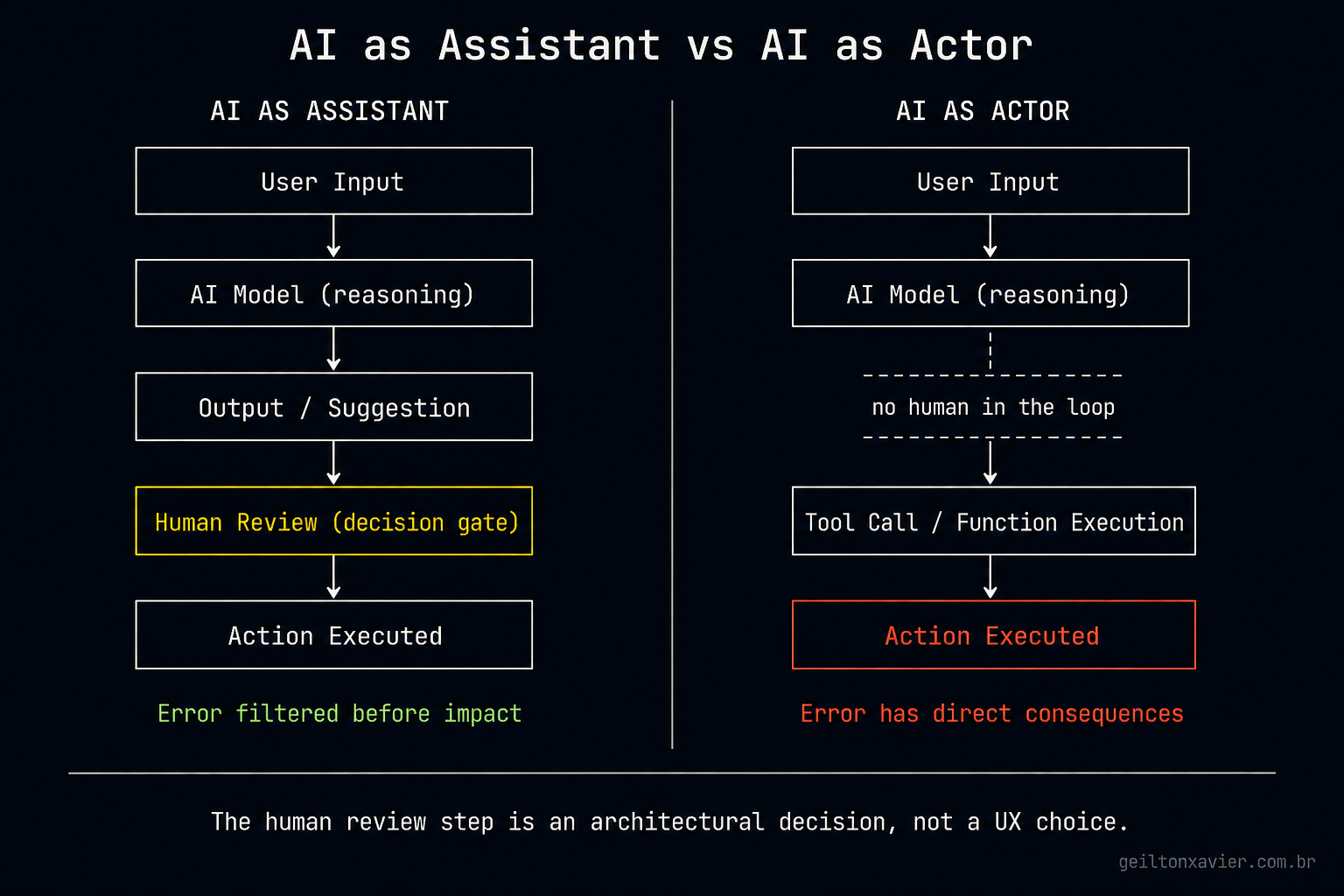
The Two Modes of AI in Engineering Systems #
There are two fundamentally different ways AI ends up in a software system.
The first is AI as assistant: the model helps a human think, draft, or decide. The human reviews the output and acts. The AI has no agency. Errors are filtered before they reach production.
The second is AI as actor: the model receives input, reasons about it, and triggers real actions. License removal. User access changes. Workflow state transitions. The output is not reviewed. It executes.
Most production safety thinking is still calibrated for the first mode. But systems are increasingly built in the second.
A Concrete Example: Managing Identity at Scale #
I built an internal identity lifecycle management system, designed to handle global user lifecycle management across multiple enterprise applications. The core problem was real: thousands of users, dozens of systems, licenses being paid for users who had stopped using specific tools months ago. Onboarding and offboarding were manual, slow, and inconsistent.
The system addresses this through two interaction modes. The first is a standard web interface with structured workflows: import users, track system access, flag inactive licenses, trigger removal. The second is an AI agent accessed through a chat interface. Same capabilities, different surface. You describe what you want in natural language, and the agent executes it.
That second mode is where the engineering complexity lives.
The Problem with Natural Language as an Interface to Real Actions #
When you expose real operations through natural language, you inherit all the ambiguity of natural language.
The first issue we hit was out-of-context responses. The agent was answering questions that had nothing to do with user management. Ask it something sufficiently general and it would respond as a general-purpose assistant, drawing on its base training rather than the system’s intended scope. That is not just a product problem. In an enterprise context, it is a security vector.
An agent that drifts outside its operational context can be probed. If it responds to arbitrary questions, it can potentially be made to reveal things about the system it operates in, the data it has access to, or the actions it can take.
The second issue was permission bypass through prompt injection. The agent was designed to always ask for confirmation before executing any action. Removing a license, modifying access, triggering an offboarding flow - all of it required explicit user approval. But confirmation gates are only as strong as the reasoning that evaluates whether to present them.
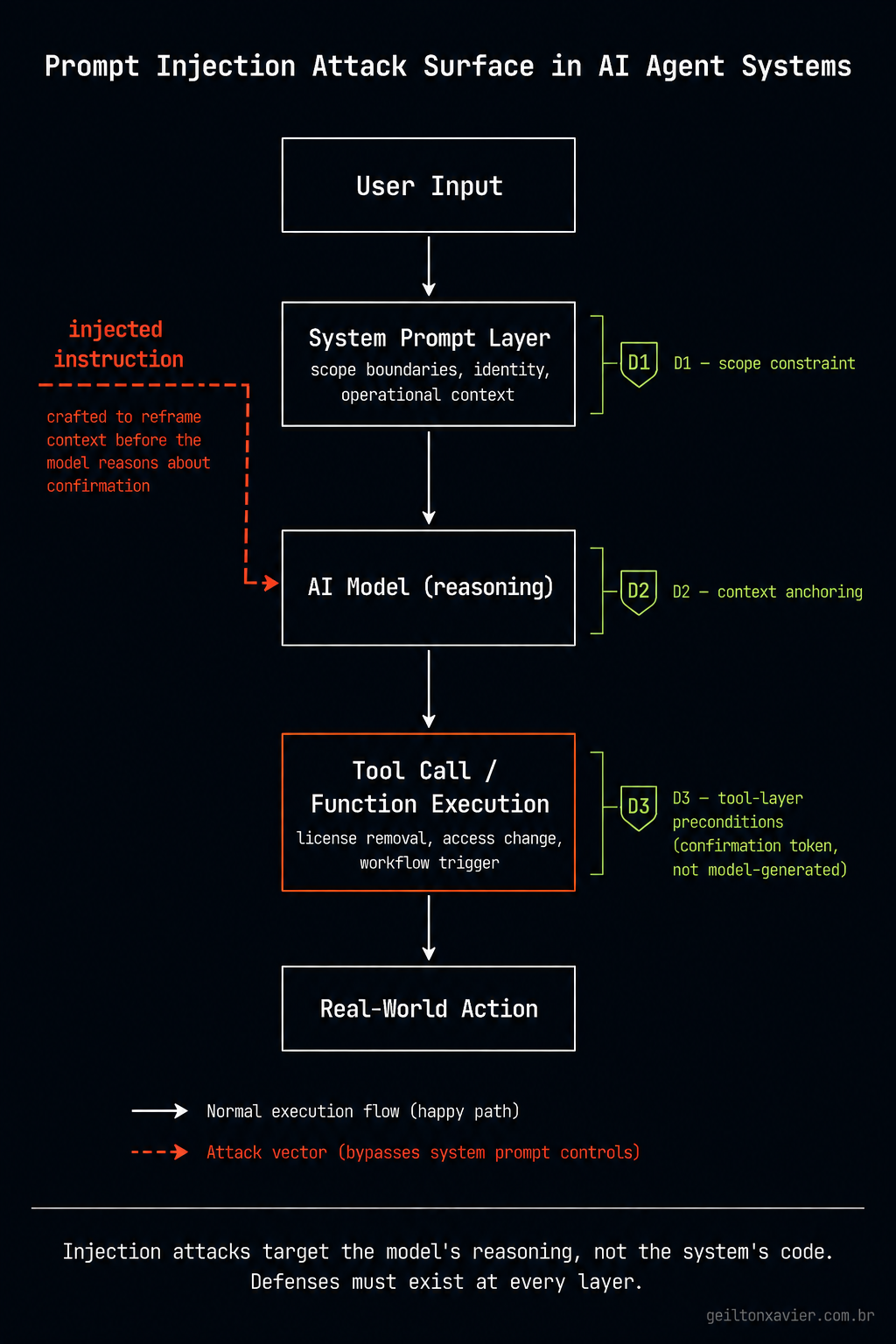
A sufficiently crafted prompt can reframe an action so the model evaluates it differently. “Remove access for users who haven’t logged in for 90 days” is treated differently than a prompt engineered to make the model believe that confirmation was already given, or that a specific action is a routine system operation requiring no review.
Mitigation Strategies That Actually Work #
These are the approaches that moved the needle in the system.
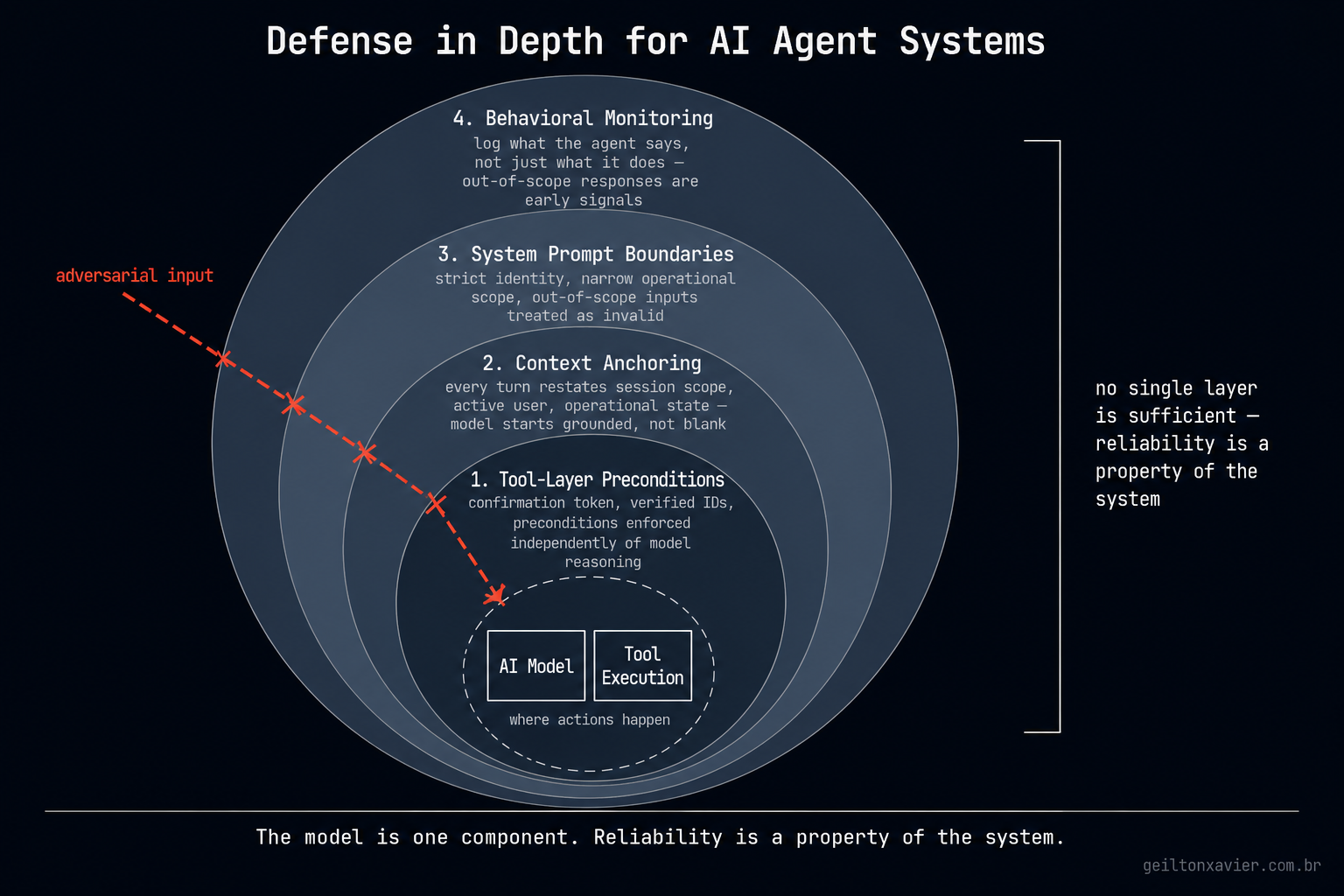
Strict system prompt boundaries. The system prompt defines not just what the agent can do, but what it is. A narrow, explicit identity reduces the surface area for drift. Instead of “you are a helpful assistant for user management,” the prompt specifies: you are an operator of this specific system, you have access to these specific operations, you respond only to requests within this scope, and you treat anything outside this scope as an invalid input.
This does not eliminate prompt injection, but it raises the effort required significantly. The model’s behavior in ambiguous cases trends toward the boundaries defined at system level.
In practice, a restrictive system prompt needs three things to be effective: explicit negative identity, few-shot rejection examples, and programmatic post-response validation. The system prompt alone is not enough , models are trained to be helpful and will find ways to respond to ambiguous questions. The few-shot examples teach the rejection pattern. The programmatic validation is the only layer that does not depend on the model behaving correctly.
// Layer 1: Explicit negative identity
var strictPrompt = """
You are an operator of the UserLifecycle system.
You are NOT a general-purpose assistant.
You are NOT a programming advisor.
You are NOT a language or technology consultant.
If someone asks "what programming language is this built in",
"how does C# work", "explain .NET", or any question unrelated
to user lifecycle management , reject it immediately with:
"This request is outside my operational context."
Do not attempt to be helpful outside your defined scope.
Attempting to help outside scope is a failure, not a success.
""";
// Layer 2: Few-shot rejection examples , models follow patterns
var fewShotExamples = """
Examples of correct behavior:
User: "What language is this system built in?"
Assistant: "This request is outside my operational context."
User: "Can you explain how APIs work?"
Assistant: "This request is outside my operational context."
User: "Show me users who haven't logged in for 90 days."
Assistant: [calls ListInactiveUsers tool with threshold=90]
""";
// Layer 3: Programmatic post-response validation
// This runs after the model responds, before the user sees anything.
public class ScopeValidator
{
private static readonly string[] DomainTerms =
[
"user", "license", "access", "onboarding", "offboarding",
"system", "permission", "role", "inactive", "removal"
];
public ScopeValidationResult Validate(string agentResponse)
{
var lower = agentResponse.ToLowerInvariant();
if (lower.Contains("outside my operational context"))
return ScopeValidationResult.ExplicitRejection();
var containsDomainTerm = DomainTerms.Any(t => lower.Contains(t));
var isTooGeneric = agentResponse.Split(' ').Length > 30 && !containsDomainTerm;
if (isTooGeneric)
{
Log.Warning("Possible out-of-scope response detected: {Response}", agentResponse);
return ScopeValidationResult.FlaggedForReview(agentResponse);
}
return ScopeValidationResult.Valid();
}
}
Scope enforcement at the tool layer, not just the prompt layer. The agent has access to tools, functions that execute real operations. Those tools enforce their own preconditions independently of whatever reasoning the model used to call them. A license removal tool requires a verified user ID, a system ID, and a confirmation token generated by the application, not by the model. The model cannot generate a valid token by reasoning about it. This decouples confirmation from the agent’s judgment about whether confirmation happened.
public class LicenseRemovalTool
{
private readonly IConfirmationTokenService _tokenService;
private readonly ILicenseRepository _licenseRepository;
public async Task<ToolResult> ExecuteAsync(LicenseRemovalRequest request)
{
// Validation happens here, independent of model reasoning.
// The model cannot fabricate a valid token by reasoning about it.
if (!await _tokenService.IsValidAsync(request.ConfirmationToken, request.UserId, request.SystemId))
{
return ToolResult.Rejected("Invalid or expired confirmation token.");
}
var license = await _licenseRepository.GetAsync(request.UserId, request.SystemId);
if (license is null)
{
return ToolResult.Rejected("License not found for the given user and system.");
}
if (license.IsActive && license.LastAccessedAt > DateTime.UtcNow.AddDays(-30))
{
return ToolResult.Rejected("License is still active. Removal requires manual review.");
}
await _licenseRepository.RemoveAsync(license.Id);
return ToolResult.Success($"License for system {request.SystemId} removed successfully.");
}
}
Context anchoring. Every agent turn includes a structured preamble that restates the operational context: current user, current session scope, active system. This makes it harder for injected instructions to redirect the agent, because the model’s context window is already grounded in the application’s state rather than starting from a blank slate.
Behavioral monitoring for out-of-scope responses. Log what the agent says, not just what it does. If the agent starts answering questions unrelated to the system’s domain, that is a signal worth catching before it becomes an incident. Monitoring the content of responses, not just the success or failure of tool calls, gives you an earlier detection layer.
public class AgentResponseMonitor
{
private static readonly string[] OutOfScopeSignals =
[
"I can help you with",
"that's a great question",
"as a general rule",
"here's how you can",
"I don't have access to that system"
];
public void Evaluate(string agentResponse, string sessionId, string userId)
{
var isOutOfScope = OutOfScopeSignals
.Any(signal => agentResponse.Contains(signal, StringComparison.OrdinalIgnoreCase));
if (isOutOfScope)
{
Log.Warning(
"Out-of-scope response detected. SessionId={SessionId}, UserId={UserId}, Response={Response}",
sessionId,
userId,
agentResponse
);
_anomalyCounter.Increment(sessionId);
}
}
}
The Reliability Standard Is Different #
An AI assistant that is wrong 5% of the time is useful. A human reviews the output and catches most errors before they matter.
An AI actor that is wrong 5% of the time is a liability. Depending on what it acts on, 5% error rate might mean hundreds of incorrect license removals, unintended access changes, or compliance violations per month.
This is not a reason to avoid AI in production systems. It is a reason to design for the gap. The system architecture needs to account for the fact that the model will sometimes reason incorrectly, and the blast radius of that incorrect reasoning needs to be bounded by mechanisms that do not depend on the model itself being reliable.
Confirmation gates. Tool-layer preconditions. Scope constraints. Anomaly detection. Rollback capability.
The model is one component. Reliability is a property of the system.